- 四角号碼とは?
伝統的な部首と画数による検字法は、「再→冂部」などのように部首の抽出がわかりにくかったり、「問→門部でなく口部」などのように字形のみならず意味を考慮しているため不統一だったり、なかなか大変です。部首がわからない場合の最後の手段は総画数ということになりますが、画数を数え間違えたり、同画数の字が膨大に存在したり、これまたなかなか大変です。
民国期(1920年代)に商務印書館の王雲五氏によって開発された「四角号碼」は、部首・画数・筆順・音・意味などにとらわれず、純粋に漢字の四隅の字画の形に基づくコードによって検字しようというものです。最初は少々とっつきにくいかもしれませんが、比較的簡単に習得できる検字法です。伝統的な部首や画数や筆順に基づく漢字教育を受けていない外国人などには逆にわかりやすい方法といえるかもしれません。最初は『辭源』など商務印書館の辞書に採用されましたが、その後は広くさまざまな辞書や索引に使用されており、『二十四史人名索引』など、四角号碼索引だけしかない索引もあるほどなので、中国とかかわりのある学問をするなら四角号碼のスキルは必須です。
日本でも『大漢和辞典』(1960)がいちはやく採用したので、四角号碼紹介の歴史は一応長いのですが、あとは同じ大修館書店の辞典の一部に採用されている程度で四角号碼索引はちっとも普及していません。大漢和の利用者ですら四角号碼索引を使っている人はほとんどいないのではないでしょうか。中国畑の学生も四角号碼を使っておらず、四角号碼オンリーの索引を前にして戸惑っている始末です。そのせいなのか、三省堂の『クラウン中日辞典』は、四角号碼索引はないくせに、本文の親字の後にその字の四角号碼コードのみ載せているという、実に風変わりなことをしています。「四角号碼索引は要らないけど、四角号碼オンリーの索引を利用するために、コードだけは知りたい」ということなのでしょうか。四角号碼はここまで嫌われているようです。
確かに四角号碼は習得にちょっとコツが要り、最初は字の検索に苦労します。それが嫌われる理由かもしれません。しかし慣れれば最も快適な検索法といえます。今までは部首→画数と二度の手間をかけ、画数を数えるのには手を空中で動かしながら時間をかけていたものが、四隅の形だけで検索できるようになるのですから。さらにコンピュータならテンキーだけでちょこちょこと最大5桁の数字を入力するだけで目的の字がポンと現れる、この快感をぜひ多くの人に味わってもらいたいものです。ぜひ四角号碼に慣れてください。
ところで「号碼」などという日本語はありませんし、日本語では「角」を「隅」の意味で使うことはあまりありません。ですから本来なら日本語の文脈では「四角号碼」を「四隅コード」のように訳すべきなのでしょうが、大漢和辞典でも「四角号碼」と呼んでいるなど日本でもこの用語が定着しているので、そのまま四角号碼(しかくごうま)と呼ぶことにします。
- 基本原則
四角号碼の基本原則は次の通りです。
- 漢字の筆画を10種類の要素に分類して0~9のコードを割り当てる……
コード表は以下のとおりです。
| コード | 名前 | 形 | 例 |
|---|
| 説明 |
|---|
| 0 |
ナベブタ |
 |
 |
| 点+横線。隹の右上も含む。广や疒のようにナベブタの左側で他の筆画と続くものも含むが、宀や之のようにナベブタの右側で他の筆画と続いているものは3(点)でとる。 |
| 1 |
横 |
 |
 |
| 横画,右へのハネ |
| 2 |
縦 |
 |
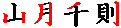 |
| 縦画,左へのハネ |
| 3 |
点 |
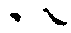 |
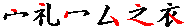 |
| 点,右ハライ,辶の末筆(よって辶の字は必ず3x30) |
| 4 |
交叉 |
 |
 |
| 2画が交叉 |
| 5 |
串ざし |
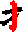 |
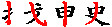 |
| 1画が複数画を貫く |
| 6 |
四角 |
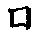 |
 |
| 尸皿門などのように四角のどれかの端が伸びているものは7(カギ)でとる。 |
| 7 |
カギ |
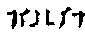 |
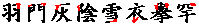 |
| 横画+縦画。カギの両端は別の要素とするので「司」は7060ではなく1762 |
| 8 |
八 |
 |
 |
| 八の字とその変形。他と交叉しているもの(大など)を除く |
| 9 |
小 |
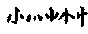 |
 |
| 小の字とその変形。ただし学の上部・水・恭の下部・緑の右下・業の上部などは除く |
※ピンク(0456789)は複数の筆画からなっているものです。グリーン(123)かピンクか迷ったらピンクを優先します。
- 左上→右上→左下→右下の要素のコードを並べて4桁のコードにする……次の例のとおりです。

ただし実際には、これだけではまるきり同じコードになってしまう字が多すぎるので、「附角」とよばれるもう一箇所(後述)の要素のコードをあとにつけた5桁のコードで検字します。
- 字の最上部または最下部に、上記コード表の要素が一つしか存在しない場合は、それが左・中央・右のどこにあろうと「左上」(または「左下」)とし、右上(または「右下」)は0とします。

また、すでにコード化した要素が他の隅にまたがっている場合(たとえば、左上の要素が同時に右上でもある場合)は、そこで再びコード化するのでなく、0とします。
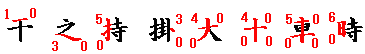
このように0は、ナベブタ形要素のコードとしてだけでなく「空白」という意味にもなるので注意してください。
- 「行(ゆきがまえ)・囗(くにがまえ等)・門(もんがまえ)・鬥(たたかいがまえ)」から構成されている字は、四隅がすべて同じなので、このままではすべて同じコードになってしまいます(囗は伝統的部首としての「くにがまえ」に属する字のみならず「田」なども含みます)。そこでこれらの字のみ例外的に、3桁め(左下)と4桁め(右下)は、これらの「かまえ」の内部の要素の左下と右下の要素からとります。ただしこれらの「かまえ」の上下左右に別の筆画がついている場合は、通常通りのとり方をします。
衍=2210、因=6043、閉=7724、鬬=7712
蘅=4422、茵=4460、瀾=3712
- 上記2で書いたように、これだけではまるきり同じコードになってしまう字が多すぎるので、末尾にもう1桁、「附角」とよばれるもう一箇所の要素のコードをつけます。
それはどこの要素かというと、右下隅要素のすぐ上部にある要素です。もしそこが右上隅要素や左上隅要素と同一であったりしてすでにコード化されている場合は、0(空白)とします。例を見てください。

附角としてとれる要素は、単に「右下隅要素のすぐ上部」というだけでなく「先端があらわれている」という条件が必要です。たとえば上記の「難」では「隹」の内部の筆画が附角になるわけですが、タテの筆画をとれば5、ヨコの筆画をとれば4ということになります。しかしタテの筆画のほうは先端が両方とも他の筆画にぶつかっておりあらわになっておりません。そこで4のほうをとるというわけです。
附角のコードは44710のように小さい字で書きます。
- 補足事項
- 独立した筆画、平行の筆画は、高低にかかわりなく、最も左、最も右のものをとります。
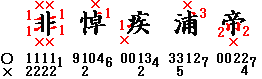
- 最も左、最も右であっても、その上や下に他の筆画がある場合は、上にあるものを左上(右上)とし、下にあるものを左下(右下)とします。
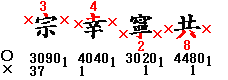
- 複筆(コード表のピンク、0456789の要素)が2つとれる場合は、より高いものを左上(右上)とし、より低いものを左下(右下)とします。
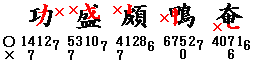
ここまで(補足事項の1-3)は、伝統的にこういう順番で説明されているのですが、逆に3→2→1という順番に読むとわかりやすいと思います。つまり、隅に筆画が2つあるとき、より上(より下)のものをとるのか、より左(より右)のものをとるのかで迷うことが多いのですが、それは「隅の筆画がどちらも複筆(ピンクつまり0456789)ならば上下優先」→「その他の場合は、ハッキリ上下関係になっているときは上下優先、でなければ左右優先」ということです。
- ナナメのハネの下に別の筆画があるときは、ハネの部分ではなく、その下の筆画のところを左下(右下)とします。

- 左上のハネは左上としますが、左上以外の部分にあるときは、ハネではなくその右側にある筆画を右上とします。
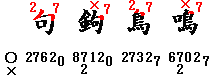
- 字体は楷書に従います。必ずしも明朝体とは一致しないので注意してください。

日本でも83年と90年のJISの字体の相違が話題になっており、単に字体の違いにすぎないものを別字であるかのような認識をする人が多数いることを考えれば、これはけっこう大問題です。
「比」の左下は明朝体では「上」のようになっているので1かと思いきや、楷書では「ヒ」のようになるので7です。これは日本でも同様なのでまだいいのですが、「戸」の上部は中国の楷書では点になるので3でとります。同様に編だの遍だのの右上もすべて3になります。日本の楷書では横棒になるのが普通だと思いますので注意が必要です。
「點」(61360)は、「灬」を下全体に配置する書体の場合61336になってしまいます。この字については辭源も大漢和辞典も61360に統一しているようですが、「蘸」は、辭源では「灬」を右のみに配置して44631)、大漢和辞典では「灬」を下全体に配置して44331としています。こういう例は本当に困りますが、どちらでも検索できるような配慮をすべきなのかもしれません。
- 新華字典特有の方式
四角号碼が考案されてからすでに80年ほど経過しましたが、その間いろいろと流儀が変化してきました。特に大陸で簡体字を採用してからは、簡体字に対応してけっこう流儀が変化したところがあります。後述のように当サイトの四角号碼は、『辭源』で採用されたオリジナルに近い方式を採用していますが、大陸の簡体字については新華字典の方式を採用しています。そこで新華字典での方式の違いを簡単にまとめます。
- 従来8としなかった「大」の字の下部を8とします(大:40030→40800)。
- 従来9としなかった学の上部・水・緑の右下を9とします(学:32407→90407)。
- 又や牙の左上をカギとみなして7とします(又:17400→77400)。なお、簡体字の馬ヘンの左上は1です(驳:14140)。
- 母や毋の下部を50でなく75とします。よって母や毋は77500→77750。また敏は88540→88740。
- 夂の下部を24でなく40とします(夏:10247→10407)。
- 比や北などの右上を横(1)でなく縦(2)とみなします(比:21710→22710)。
- 行がまえの字はすべて21221とします。
- 友や左などで、左下隅を4でなく、その下の又や工の部分とします(友:40047→40407)。同様に差は80211→80102。
- 従来、耳そのものの下部は40でしたが耳へんになると左下を1としていたものを、やはり4とします(聴:14136→14436)。
- 字の下部が左右にかたよっている場合、空白部を0とします(弓:17207→17027、戸:30277→30207)。
- 附角について、「先端があらわれている」という条件を撤廃しました。ですから「隹」の附角は4でなく5になります。
- その他の注意事項
以上のほかに陥りやすい誤りを列挙します。
- うかんむりは0でなく3です(宇:30401)
- ナナメ右に下がるものは3です(瓜:72230)が、さらにハネるものは、ハネる前にいったん水平になっているとみなして1です(風:77210)。ハネがカギ形に見えるからといって7にしてもいけません。
- 簡体字の「食へん」の上部は8でなく2です(饥:27716)
- しめすへん、ころもへんの下部は9でなく2です(礼:32210)
- 当サイトの四角号碼について
四角号碼の方式は時期によって少しずつ改良を加えられているので、辞書によって細かな違いがあります。そのほとんどは、四隅の位置の解釈の違いや、要素のとり方の違いです。そこで当「青蛙亭漢語塾」では、勝手に四角号碼の値を決めるのではなく、必ず典拠に基づいたものを用いています。具体的には、
- 『辭源』(商務印書館、1947)
- 『大漢和辞典修訂版』(大修館書店、1987)……僻字など、1に未収録の字
- 『広漢和辞典』(大修館書店、1982)……主に日本新字体など、1-2に未収録の字
- 『新華字典』(商務印書館、2002)……主に大陸の簡体字など、1-3に未収録の字
という優先順位で四角号碼の値を決定しており、流儀の違いの統一はあえて行っておりません。前述のように、『新華字典』では四隅をとる流儀がけっこう変更されました。大陸の簡体字では四隅の取り方の変更が必要になる場合がありますので、検索するときは注意してください。
ただし、「繁体字は辭源方式、簡体字は新華字典方式」というのでは混乱のもとになりますので、上記4辞典に掲載されている四角号碼は「四角号碼の変種」として、たとえば繁体字であっても新華字典方式で、簡体字であっても辭源方式で引けるよう許容するようにしています。
四角号碼の入力作業にあたっては、上記の辞典にいちいち直接あたるのは大変なので、以下のような簡便な方法を利用しました。
- 漢字情報一覧説明@古代凝視空間……JIS漢字のデータベースですが、大漢和辞典≒辭源方式の四角号碼が入力されているので流用しました。
- 四角號碼新詞典……香港商務印書館版。繁体字、辭源方式。本文は四角号碼順なのですが、巻末にピンイン索引と総画索引があるので、繁体字の四角号碼確認&入力に利用しました。
- 四角号码新词典……北京商務印書館版。簡体字、新華字典方式。本文は四角号碼順なのですが、巻末にピンイン索引と部首索引があるので、簡体字の四角号碼確認&入力に利用しました。
- 三省堂『クラウン中日辞典』……ピンイン順の中日辞典ですが、本文中に四角号碼(新華字典式)を載せているので、簡体字の四角号碼確認&入力のに利用しました。もっともこの辞典は、簡体字の馬ヘンを7とする点で新華字典式と違います。
「〇」(漢数字としてのゼロ)の四角号碼は新華字典によれば6000(附角ナシ)ですが、附角も0として60000とします。よって「口」と同じになります。
- 当サイトコンテンツにおける四角号碼検索法
WEB支那漢など、当サイトのコンテンツにおける四角号碼検索は、次のような方法で行います。
- 原則として先頭一致で行います。
- 12345……12345のみに一致
- 1234……12340、12341 ~ 12349に一致
- 123……123で始まるすべてのコードに一致
- .(ピリオド)または?(クエスチョン)を任意の1文字に合致するワイルドカードとして使用できます。
- 123?5……12305、12315、12325 ~ 12395に一致
- 1.3……左上が1、左下が3のすべてのコードに一致
- *(アスタリスク)を任意の0文字以上数文字に合致するワイルドカードとして使うことができます。なお、*を用いたときに限り、先頭一致でなく完全一致で検索します。
- 12*5……12で始まり5で終わるすべてのコードに一致
- *5……附角コードが5であるすべてのコードに一致
- 四角号碼に慣れるために
最初のうちは四隅の判断に迷ってなかなか目的の字を検索できないかと思いますが、そういうときは当サイトのWEB支那漢などで似ている他の字の四角号碼を参照するのが、四角号碼に慣れるコツです。
四角号碼索引をつけた辞書はいろいろありますが、意外なことに、四角号碼は索引の中でしか出てこず、「この字の四角号碼はいくつだ」という情報を本文中に載せているものは絶無です。『四角號碼新詞典』のように本文が四角号碼順になっているものを除けば、三省堂の『クラウン中日辞典』がおそらく唯一の例外です。「四角号碼なんて本文中に載せるような高級な情報ではなく、所詮は索引用のあだ花」だと思っているのでしょうか。しかし四角号碼に慣れないうちは、既知のいろいろな字が四角号碼だとどうなるかを見たいものです。大変に便利な四角号碼を多くの人に広めるチュートリアルの役割をになわんと、WEB支那漢ではちゃんと四角号碼を表示することにしました。
たとえば「『斁』をひきたいんだが右側に来る攵をどうコード化するかがわからない」という場合、「教」だの「数」だの、適当な「攵」のつく字を入力して四角号碼をしらべれば、右上8、右下4、附角0であることがわかります。これを参考に68440とすればよいですし、ワイルドカードを用いて?8?40とすれば「攵」のつく字を残らず検索することもできます(ただし「杵」などもヒットしてしまいますし、「攵」そのものは80400となってヒットしないことにも注意)。こんなふうに他の字のコードとワイルドカードを適宜組み合わせて四角号碼に慣れてください。
おまけ
四角号碼が作られたとき、かの有名な胡適が、「四角号碼を記憶するための歌」を作りました。中国語で発音しないと意味がありませんが、念のため掲げます。
| 一橫二垂三點捺 |
| 點下帶橫變零頭 |
| 叉四插五方塊六 |
| 七角八八小是九 |
この歌は後に出た『四角號碼新詞典』では次のように改められました。『新華字典』には今でもこの版の覚え歌が掲載されています。
| 横一垂二三点捺 |
| 叉四插五方框六 |
| 七角八八九是小 |
| 点下有横变零头 |
四角号碼については次のページも参考になるかと思います。
- 四角号碼入門
- 四角号碼検索 @ 中国語学習室
実生活への応用例。四角号碼は附角を除けば4桁なので、キャッシュカードやクレジットカードなどの暗証番号に使えます。最近では生年月日や電話番号など推測されやすい暗証番号を用いた場合は犯罪に際して銀行の保障を受けられなかったり、そもそもそういう暗証番号を拒否する銀行も増えているので、暗証番号を何にしようかお悩みの方は、ご自分の名前のどれかの文字の四角号碼を使うという手が考えられます。もっとも実際にこの手を用いたことによるリスクに関して当方は一切関知しませんのでご注意を。
|
